


[Part 1/3] Verida Technical Litepaper: Self-Sovereign Confidential Compute Network to Secure Private AI
Verida’s mission has always been clear: empower individuals to own and control their data. Now, we’re taking it further.

This is the first of three posts over the next three weeks to release the “Verida Technical Litepaper: Self-Sovereign Confidential Compute Network to Secure Private AI”
Introduction
Verida’s mission has always been clear: empower individuals to own and control their data. Now, we’re taking it further.
This Technical Litepaper presents a high-level outline of how the Verida Network is growing beyond decentralized, privacy preserving databases, to support decentralized, privacy-preserving compute optimized for handling private data. There are numerous privacy issues currently facing AI that web3 and decentralized physical infrastructure networks can help solve. From Verida’s perspective, this represents an expansion of our mission from allowing individuals to control their data to introducing new and powerful ways for users to benefit from their data.
Current AI Data Challenges
We are running out of high-quality data to train LLMs
Public internet data has been scraped and indexed by AI models, with researchers estimating that by 2026, we will exhaust high-quality text data for training LLMs. Next, we need to access private data, but it’s hard and expensive to access.
Private enterprise and personal AI agents need to access private data
There is a lot of excitement around the next phase of AI beyond chat prompts. Digital twins or personal AI agents that know everything about us and support every aspect of our professional and personal lives. However, to make this a reality AI models need access to private, real time context-level user data to deliver more powerful insights and a truly personalized experience.
Existing AI platforms are not private
The mainstream infrastructure providers powering the current generation of AI products have full access to prompts and training data, putting sensitive information at risk.
AI trust and transparency is a challenge
Regulation is coming to AI and it will become essential that AI models can prove the training data was high quality, ethically sourced. This is critical to reduce bias, misuse and improve safety in AI.
Data creators aren’t being rewarded
User-owned data is a critical and valuable resource for AI and those who create the data should benefit from its use. Reddit recently sold user data for $200M, while other organizations have reached similar agreements. Meta is training its AI models on user data from some countries, but excluding European users due to GDPR preventing them from doing so without user consent.
Verida’s Privacy Preserving Infrastructure
Verida has already developed the leading private decentralized database storage infrastructure (see Verida Whitepaper) which provides a solid foundation to address the current AI data challenges.
Expanding the Verida network to support privacy-preserving compute enables private, encrypted data to be integrated with leading AI models, ensuring end-to-end privacy, safeguarding data from model owners. This will unlock a new era of hyper-personal and safe AI experiences.
AI services such as ChatGPT have full access to any information users supply and have already been known to leak sensitive data. By enabling model owners access to private data, there is increased risks of data breaches, imperiling privacy, and ultimately limiting AI use cases.
There are three key problems Verida is solving to support secure private AI:
Data Access: Enabling users to extract and store their private data from third party platforms for use with emerging AI prompts and agents.
Private Storage and Sharing: Providing secure infrastructure allowing user data to be discoverable, searchable and accessible with user-consent to third party AI platforms operating within verifiable confidential compute environments.
Private Compute: Provide a verifiable, confidential compute infrastructure enabling agentic AI computation to securely occur on sensitive user data.
Supporting the above tasks, Verida is building a “Private Data Bridge”, allowing users to reclaim their data and use it within a new cohort of personalized AI applications. Users can pull their private data from platforms such as Google, Slack, Notion, email providers, LinkedIn, Amazon, Strava, and much more. This data is encrypted and stored in a user-controlled private data Vault on the Verida network.
It’s important to note that Verida is not building infrastructure for decentralized AI model training, or distributed AI inference. Rather, Verida’s focus is on providing a high performance, secure, trusted and verifiable infrastructure suitable for managing private data appropriate for AI use cases.
We have relationships with third parties that are building; private AI agents, AI data marketplaces and other privacy-centric AI use cases.
Comparing Current AI Solutions
AI solutions can be deployed primarily through two methods: cloud-based/hosted services or on local machines.
Cloud-based AI services, while convenient and scalable, expose sensitive user data to potential risks, as data processing occurs on external servers and may be accessible to third parties.
In contrast, local AI environments offer enhanced security, ensuring that user data remains isolated and inaccessible to other applications or external entities. However, local environments come with significant limitations, including the need for technical expertise that is not available to the majority of users. Moreover, these environments often face performance challenges; for instance, running large language models (LLMs) on standard consumer hardware is typically impractical due to the high computational demands.
Verida’s Confidential Storage and Compute infrastructure offers alternatives to these approaches.

Apple has recently announced Private Cloud Compute that provides a hybrid local + secure cloud approach. AI processing occurs on a local device (ie: mobile phone) by default, then when additional processing power is required, the request is offloaded to Apple’s servers that are operating within a trusted execution environment. This is an impressive offering that is focused on solving important security concerns relating to user data and AI. However, it is centralized, only available to Apple devices and puts significant trust in Apple as they control both the hardware and attestation keys.
Self-Sovereign AI Interaction Model
Let’s look at what an ideal model of confidential AI architecture looks like. This is an interaction model of how a basic “Self-Sovereign AI” chat interface, using a RAG-style approach, would operate in an end-to-end confidential manner.
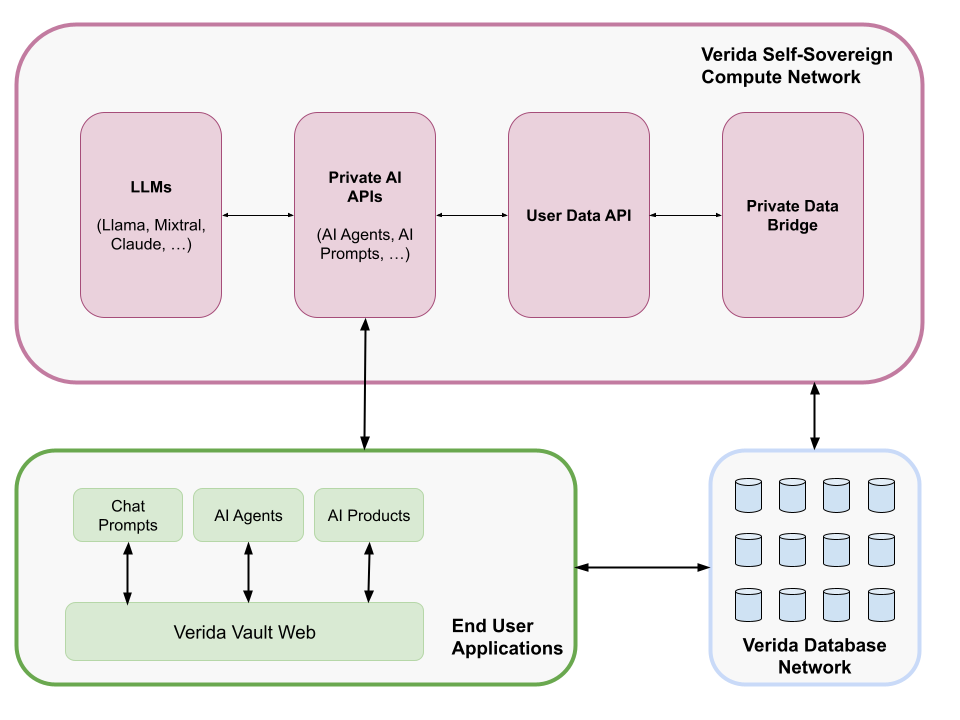
Figure 3: Self-Sovereign AI Interaction Model
The End User Application in this example will be a “Chat Prompt” application. A user enters a prompt (i.e., “Summarize the conversation I had with my mates about the upcoming golf trip”).
A Private AI API endpoint (AI Prompt) receives the chat prompt and breaks down the request. It sends a prompt to the LLM, converting the original prompt into a series of search queries. The LLM could be an open source or proprietary model. Due to the confidential nature of the secure enclave, proprietary models could be deployed without risk of IP theft by the model owner.
The search queries are sent to the User Data API which has access to data previously obtained via Verida’s Private Data Bridge. This data includes emails, chat message histories and much more.
The Private AI API collates the search query results and sends the relevant responses and original prompt to the LLM to produce a final result that is returned to the user.
Verida is currently developing a “showcase” AI agent that implements this architecture and can provide a starting point for other projects to build their own confidential private AI products.