


[Part 2/3] Verida Technical Litepaper: Self-Sovereign Confidential Compute Network to Secure Private AI

This is the second of three posts over the next three weeks to release the “Verida Technical Litepaper: Self-Sovereign Confidential Compute Network to Secure Private AI”. Read Part 1.
Confidential Compute
A growing number of confidential compute offerings are being offered by the large cloud providers that provide access to Trusted Execution Environments (TEEs). These include: AWS Nitro, Google Confidential Compute and Azure Confidential Compute. Tokenized confidential compute offerings such as Marlin Oyster and Super Protocol have also emerged recently.
These compute offerings typically allow a container (such as a Docker instance) to be deployed within a secure enclave on secure TEE hardware. The enclave has a range of verification and security measures that can prove that both the code and the data running in the enclave is the code you expect and that the enclave has been deployed in a tamper-resistant manner.
There are some important limitations to these secure enclaves, namely:
There is no direct access available to the enclave from the infrastructure operator1. Communication occurs via a dedicated virtual socket between the secure enclave and the host machine.
There is no disk storage available, everything must be stored in RAM.
Direct GPU access is typically not available within the secure enclave (necessary for high performance LLM training and inference), however this capability is expected to be available in early 2025.
The Verida network is effectively a database offering high performance data synchronization and decryption. While secure enclaves do not have local disk access (by design), it is possible to give a secure enclave a private key, enabling the enclave to quickly download user data, load it into memory and perform operations.
While enclaves do not have direct access to the Internet, it is possible to facilitate secure socket connections between the host machine and enclave to “proxy” web requests to the outside world. This increases the surface area of possible attacks on the security of the enclave, but is also a necessary requirement for confidential compute that interacts with other web services.
It is critical that confidential AI inference for user prompts has a fast response time to ensure a high quality experience for end users. Direct GPU access via confidential compute is most likely necessary to meet these requirements. Access to GPUs with TEEs is currently limited, however products such as the NVIDIA H100 offer these capabilities and these capabilities will be made available for use within the Verida network in due course.
Self-Sovereign Compute
Verida offers a self-sovereign compute infrastructure stack that exists on top of confidential compute infrastructure.
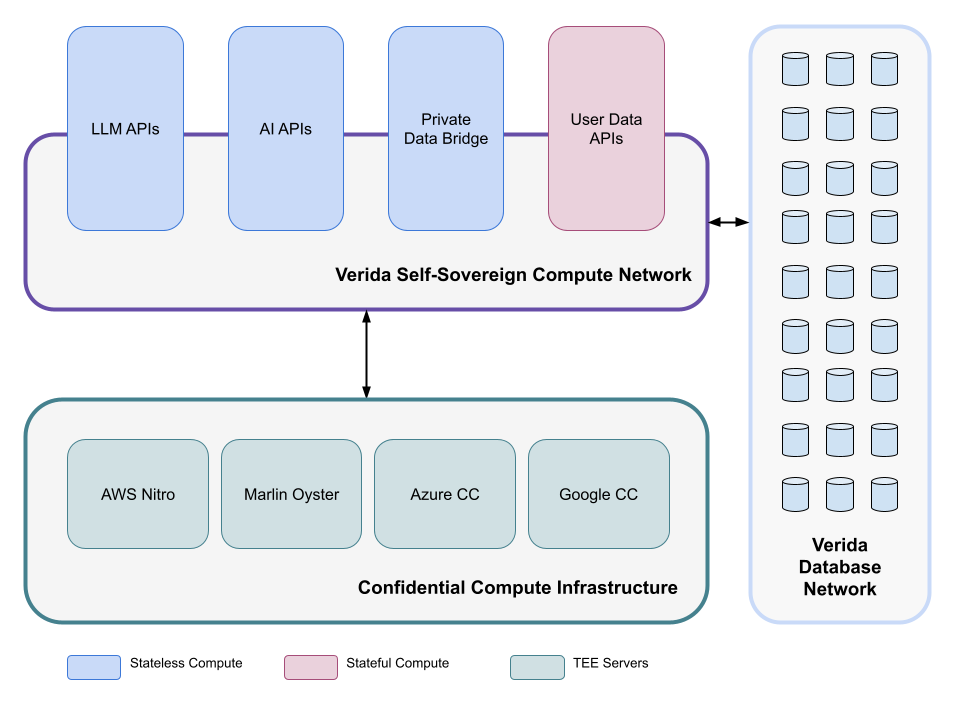
Figure 1: Self-Sovereign Compute Architecture
The self-sovereign compute infrastructure provides the following guarantees:
User data is not accessible by infrastructure node operators.
Runtime code can be verified to ensure it is running the expected code.
Users are in complete control over their private data and can grant / revoke access to third parties at any time.
Third-party developers can build and deploy code that will operate on user data in a confidential manner.
Users are in complete control over the compute services that can operate on their data and can grant / revoke access to third parties at any time.
There are two distinct types of compute that have different infrastructure requirements; Stateless Confidential Compute and Stateful Confidential Compute.
Stateless (Generic) Confidential Compute
This type of computation is stateless, it retains no user data between API requests. However, it can request user data from other APIs and process that user data in a confidential manner.
Here are some examples of Generic Stateless Compute that would operate on the network.

Figure 2: Verida Personal Data Bridge
Private Data Bridge facilitates users connecting to third-party platform APIs (ie: Meta, Google, Amazon, etc.). These nodes must operate in a confidential manner as they store API secrets, handle end user access / refresh tokens to the third-party platforms, pull sensitive user data from those platforms, and then use private user keys to store that data in users’ private databases on the Verida network.
LLM APIs accept user prompts that contain sensitive user data, so they must operate in a confidential compute environment.
AI APIs such as AI prompt services and AI agent services provide the “glue” to interact between user data and LLMs. An AI service can use the User Data APIs (see below) to directly access user data. This enables it to facilitate retrieval-augmented generation (RAG) via the LLM APIs, leveraging user data. These APIs may also save data back to users’ databases as a result of a request (i.e., saving data into a vector database for future RAG queries).
See Self-Sovereign AI Interaction Model for a breakdown of how these generic compute services can interact together to provide AI services on user data.
Stateful (User) Confidential Compute
This type of computation is stateful, where user data remains available (in memory) for an extended period of time. This enhances performance and, ultimately, the user experience for end users.
A User Data API will enable authorized third party applications (such as private AI agents) to easily and quickly access decrypted private user data. It is assumed there is a single User Data API, however in reality it is likely there will be multiple API services that operate on different infrastructure.
Here are some examples of the types of data that would be available for access:
Chat history across multiple platforms (Telegram, Signal, Slack, Whatsapp, etc.)
Web browser history
Corporate knowledge base (ie: Notion, Google Drive, etc)
Emails
Financial transactions
Product purchases
Health data
Each of these data types have different volumes and sizes, which will also differ between users. It’s expected the total storage required for an individual user would be somewhere between 100MB and 2GB, whereas enterprise knowledge bases will be much larger.
In the first phase, the focus will be on structured data, not images or videos. This aligns with Verida’s existing storage node infrastructure that provides and aids the development of a first iteration of data schemas for AI data interoperability.
The User Data API exposes endpoints to support the following data services:
Authentication for decentralized identities to connect their account to a User Data API Node
Authentication to obtain access and refresh tokens for third-party applications
Database queries that execute over a user’s data
Keyword (ie: Lucene) search over a user’s data
Vector database search over a user’s data
Connecting Stateful Compute to Decentralized Identities
Third party applications obtain an access token that allows scoped access to user data, based on the consent granted by the user.
A decentralized identity on the Verida network can authorize three or more self-sovereign compute nodes on the network, to manage access to their data for third-party applications. This is via the serviceEndpoint capability on the identity’s DID Document. This operates in the same way that the current Verida database storage network allocates storage nodes to be responsible for user data.
Secure enclaves have no disk access, however user data is available (encrypted) on the Verida network and can be synchronized on demand given the appropriate user private key. It’s necessary for user data to be “hot loaded” when required which involves synchronizing the encrypted user data from the Verida network, decrypting it, storing it in memory and then adding other metadata (i.e., search indexes). This occurs when an initial API request is made, ensuring user data is ready for fast access for third-party applications.
After a set period of time of inactivity (i.e., 1 hour) the user data will be unloaded from memory to save resources on the underlying compute node. In this way, a single User Data API node can service requests for multiple decentralized identities at once.
It will be necessary to ensure “hot loading” is fast enough to minimize the first interaction time for end users. It’s also essential these compute nodes have sufficient memory to load data for multiple users at once. Verida has developed an internal proof-of-concept to verify the “hot loading” concept with user data will be a viable solution.
For enhanced privacy and security, the data and execution for each decentralized identity will operate in an isolated VM within the secure enclave of the confidential compute node.
Stay tuned, the third and final release of the Litepaper will be made available next week.
In some instances the infrastructure operator controls both the hardware attestation key and the cloud infrastructure which introduces security risks that need to be carefully worked through, but is outside the scope of this document.